
Improving segmentation model accuracy with Test Time Augmentation
Test Time Augmentation (TTA) is a technique used to improve the accuracy of a machine learning model by generating additional predictions on modified data during inference time and combining them to produce a final (hopefully improved) prediction. TTA is useful when the model is underperforming and cannot be directly improved. While TTA is available in Fastai it does not yet work for segmentation. However, it is possible to manually implement TTA for any segmentation model regardless of modelling library you are using. This can be done by applying an augmentation function to input images before generating predictions.
To apply TTA to a Fastai model, we can define a rotate_tta function to rotate the input image tensors and an undo_pred_tta function to un-rotate the predictions to their original orientation. We can then use a loop to apply our TTA and generate predictions for each rotation. Finally, we can combine the predictions in one of many ways such as taking the maximum value for each pixel and class, averaging all the predictions, or using the minimum value for one class and the maximum value for all others (useful when you have a ‘background’ class).
Keep in mind however there is a cost to using TTA, as you are affectively running your prediction over more images, your inference time will increase significantly. For the example below, the inference time will be 3x longer than a standard get_preds call. So keep this in mind when utilising TTA.
This is how I usually get predictions in Fastai
# Build a dataloader
dl = learn_inf.dls.test_dl(image_tensors)
# Get predictions
preds = learn_inf.get_preds(dl=dl)Here are a couple of functions to perform and remove TTA rotations to images encoded as tensors.
def rotate_tta(img_tensor_batch, rotation):
tta_img_tensor = torch.rot90(img_tensor_batch,k=rotation,dims=(2, 3))
return tta_img_tensor
def undo_pred_tta(pred_tensor, rotation):
undone_pred_tta = torch.rot90(pred_tensor,k=-rotation,dims=(2, 3))
return undone_pred_ttaNow we can loop over a list of rotations, while applying TTA, getting predictions and then undoing the TTA on the predictions
tta_preds = []
for rotation in [0,1,2,3]:
# Rotate the image tensors
tta_tensors = rotate_tta(image_tensors,rotation)
# Build a dataloader with the TTA tensors
dl = learn_inf.dls.test_dl(tta_tensors)
# Get the predictions for the rotated image tensors
preds = learn_inf.get_preds(dl=dl)
# Undo the rotation of the predictions and add them to the list
tta_preds.append(undo_pred_tta(preds, rotation))
# Stack all TTA predictions into one tensor
tta_stack = torch.stack(tta_preds)Finally you need a way of combining the predictions
You could simply get the most confident prediction for each pixel and class for each image like this
final_pred = torch.max(tta_stack,dim=0)Or you could average all the predictions like this
final_pred = torch.mean(tta_stack,dim=0)Or if you are dealing with a model with a ‘background’ class like I am currently, you may wish to get min value for your ‘background’ class and get the max values for all other classes.
background_values = tta_stack[:,:,0:1]
min_background_values = torch.min(background_values,dim=0)[0]
all_other_classes = tta_stack[:,:,1:]
max_all_other_classes = torch.max(all_other_classes,dim=0)[0]
final_pred = torch.cat([min_background_values,max_all_other_classes],dim=1)Here is an example using TTA on a model I trained using the KappaSet Sentinel 2 cloud and cloud shadow segmentation dataset.
Sentinel 2 image, basic prediction, TTA prediction
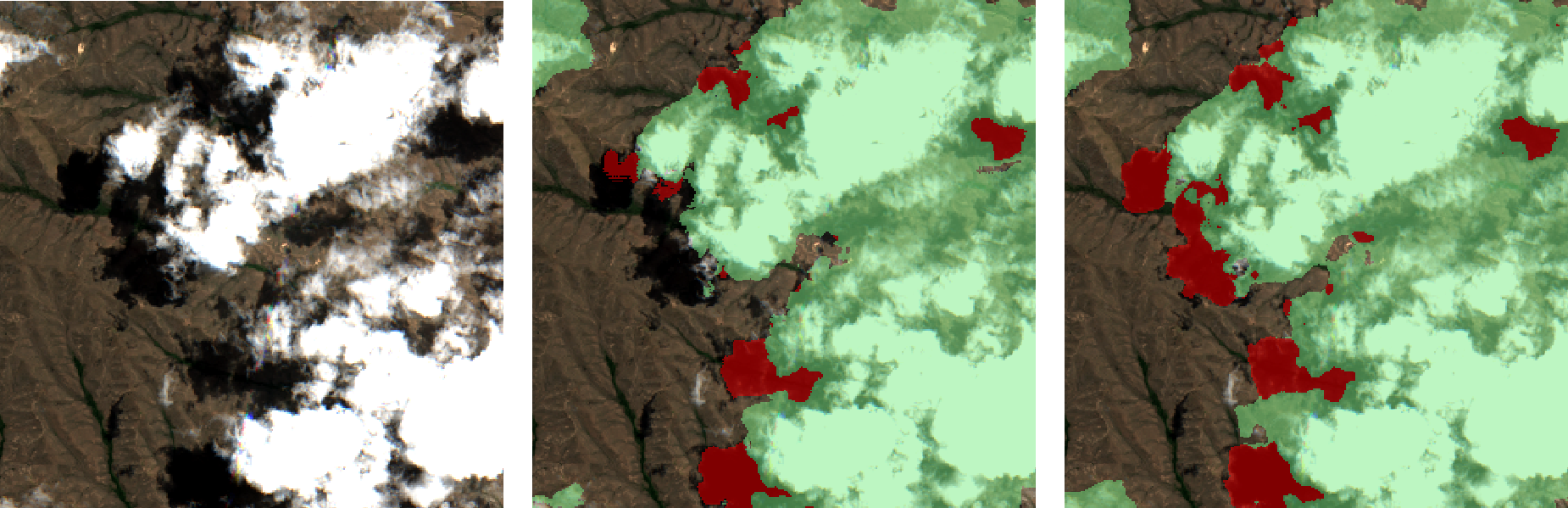
As you can see the TTA output are much improved in the cloud shadow areas, but it has increased my inference time from 1 min up to 4 mins 😥. This improvement has got me wondering if i should be applying more augmentations while training or maybe use the TTA outputs to train a new model 🤔